Step 3.2: Framework time: BUCKETIZE
Five frameworks are available and they all have their specific usage and important place in Time-Series analytics:
Let’s continue with the BUCKETIZE framework. Thanks to it, you will be able to apply some downsampling on the NASA lightcurve data.
The BUCKETIZE framework
In this tutorial we will discover the BUCKETIZE framework. It provides the tooling to put a time series data into regularly spaced buckets. A bucket corresponds to a time interval. We will use this bucket to downsample our data.
Downsampling some time series consists to reduce locally the number of points and to synchronize different series. There is several ways to process, one of the common one is to create small regular bucket into each series and to compute a value that resume this bucket. The following graphs shows this process:
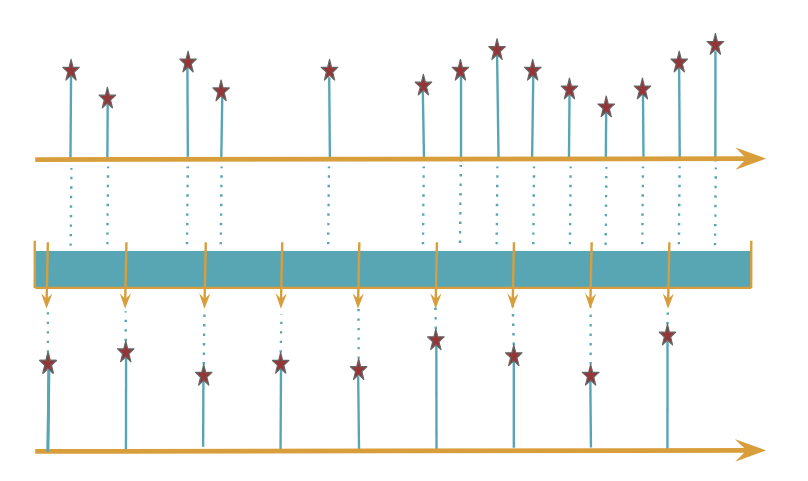
What happen in each bucket? All the points inside the selected bucket are loaded and given to a function. This function will then be executed and one value will be selected (first, last, min, max) or computed (mean, median, count, join).
The graphs below and upper show a working example of the bucketize framework. In the graph below we takes only the first bucket: there is two ticks inside with value 20 and 10. Using, for example, the function mean, this will generate only one tick at the end of the bucket with value: mean(20 and 10) which equals 15:

This how the bucketize concept works, let see how it can be implemented with WarpScript!
Input parameters
The BUCKETIZE framework takes a list of elements as parameter. This list contains one or several time series list, a bucketizer function, a lastbucket that specify when start the last bucket (0 mean this will be computed automatically), a bucketspan which is the duration of the bucket (if 0 WarpScript will compute it), and finally a bucketcount which is the number of buckets to compute (if 0 WarpScript will compute it).
Pro tips: In order to get a correct number of buckets either Bucketspan or Bucketcount have to be specified!
Pro tips 2: Bucketcount indicate the number of bucket to keep starting from the last bucket computed when a Bucketspan is also set!
// BUCKETIZE Framework
[
$gts // Series list or Singleton
bucketizer.function // Bucketize function operator
0 // Lastbucket
1 d // Bucketspan
0 // Bucketcount
]
BUCKETIZE
To get a working bucketizer, replace the function keyword by an exisiting function as first, last, mean, min, max, median, join…
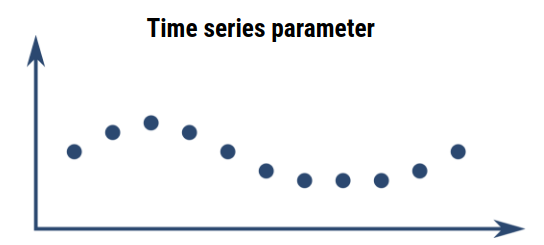
Bucketize in pictures
Let’s resume step by step each bucketize element. First BUCKETIZE requires a set of time series (Singleton or list):
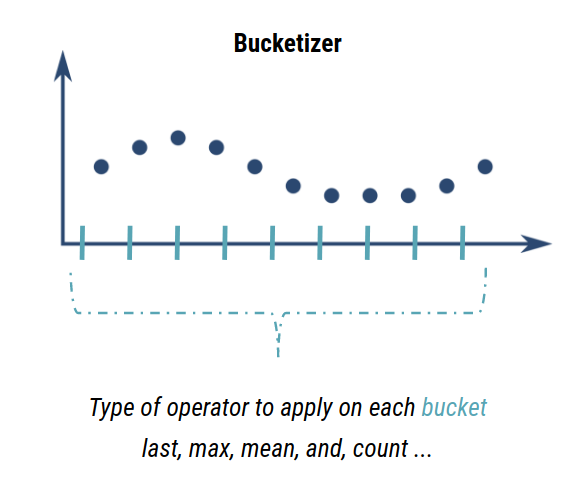
The second step consists to choose the function to apply on each bucket: first, last, mean, min, max, median, join, and others:
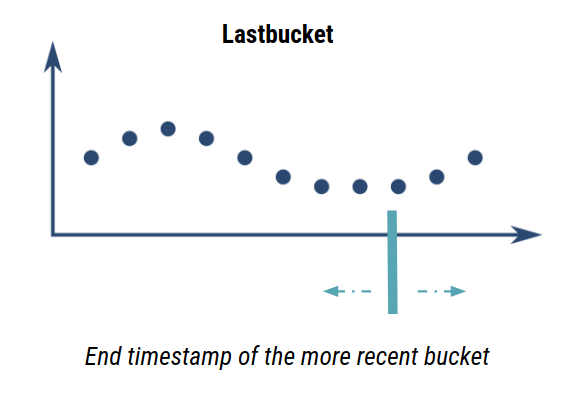
A bucketizer can be tuned according to three parameters: lastbucket which specifies the last tick (for all the series) to start computing each bucket. This parameter is very usefull to synchronize different time series.
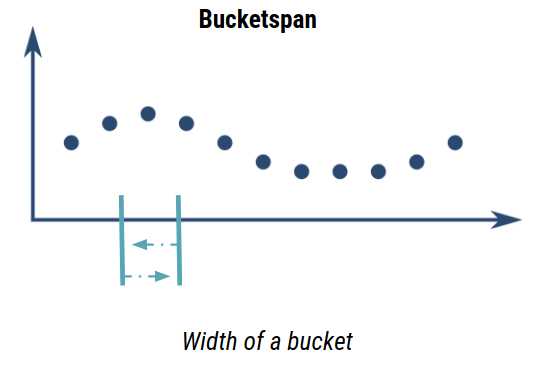
The second parameter to tun a bucketizer consists of the bucketspan: the width of each buckets:
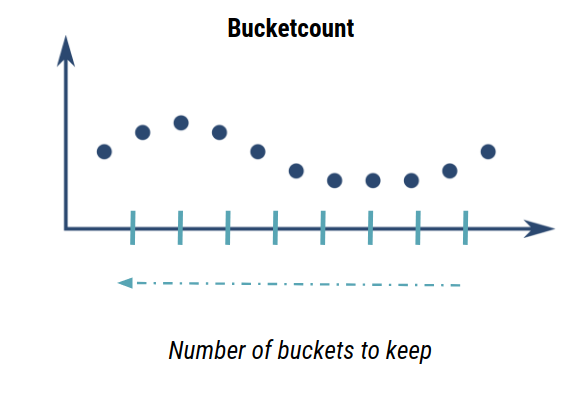
And finally the last parameter used to tun a bucketizer is the bucketcount to specify the maximal number of bucket to compute!
Now we would like to apply this specific framework to compute a downsampling operation on the NASA lightcurve data. Let’s see how to process!
Hello Exo World step
Only a single amount of series were kept in our previous step, it’s already possible to observe some drops in the data. Now we would like to write a script to detect those drops, which will means that an exoplanet could exists for this star. But first, to gain some data readibilty, a downsampling step is included. In our case we are interested in a one conserving the minimal point of each generated bucket for each series.
Let’s do it! Try the bucketizer.min with a bucketize window of 2 h.
Resume
The main goal of this step is to downsample some raw data. To do so, you used the BUCKETIZE framework, it expects on top of the stack a list of parameters containing: the time series as list or as singleton to bucketize, a bucketizer function, and three long parameter: lastbucket, bucketspan and bucketcount.
The result of this step corresponds to a downsampled list. In our case the 4 selected time series are now on top of stack containing regular bucket and one value per bucket.
To be continued
It look’s simple as first look, but truts us it isn’t. When you will be working on complex time series analytics, keep in mind this framework and try to be familiar with it! You will quickly see how it will improves your exoplanet discovery quest! In the next step, we are guiding you in the usage of an other usefull framework: MAP or how to apply the same function on all datapoints of a set of time series.